الگوریتم Viola-Jones برای تشخیص چهره
این پست در پاسخ یکی از خوانندگان قرار داده شده ( درخواست موضوع )
Viola - Jones الگوریتم AdaBoost رو با Cascade واسه تشخیص چهره ترکیب کردن . الگوریتم پیشنهادی شون می تونست چهره رو تو یه تصویر 384×288 با صرف زمانی معادل 0.067 ثانیه تشخیص بده. یعنی 15 بار سریع تر از آشکار ساز های state-of-the-art با دقتی بالاتر ، به طوریکه این الگوریتم یکی از پیشرفته ترین الگوریتم های ماشین بینایی در دهه ی گذشته تا به حال بوده . اما یه توضیح مختصر در مورد این که نقش AdaBoost در این الگوریتم چیه ؟ می تونه این باشه که : در ابتدا تصویر مورد نظر به زیر تصاویر ( 24×24 ) تقسیم بندی میشه. هر زیر تصویر بیانگر یه بردار ویژگی هستش. واسه این که محاسبات موثر و کارآمد باشه ، از یه سری ویژگی های خیلی ساده استفاده می کنیم . تمام مستطیل های ممکن تو زیر تصویر بررسی میشن. در هر مستطیل ، 4 نمونه ویژگی به کمک ماسک هایی که در شکل زیر اومده استخراج میشه . ( 4 ماسک ویژگی که واسه هر مستطیل استفاده میشه )

با هرکدوم از این ماسکها ، مجموع پیکسل های سطح خاکستری در نواحی سفید از مجموع پیکسل ها ی نواحی سیاه ، کم میشه. که این مقدار به عنوان یه ویژگی در نظر گرفته میشه. پس می تونیم اینطوری بگیم که تو یه زیر تصویر ( 24×24 ) بالغ بر 1 میلیون ویژگی می تونیم داشته باشیم ( البته این ویژگی ها خیلی سریع محاسبه میشن !! و می تونن کمتر از 1 میلیون ویژگی هم باشن مثلا 160000 در هر زیر تصویر )
هر ویژگی به عنوان یه یادگیرنده ی ضعیف در نظر گرفته می شه، یعنی :
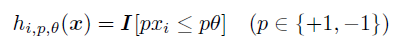
الگوریتم یادگیری پایه تلاش میکنه که بهترین کلاسیفایر ضعیف 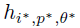 رو که ، کوچیک ترین خطا رو در کلاسبندی داره پیدا کنه.
رو که ، کوچیک ترین خطا رو در کلاسبندی داره پیدا کنه.
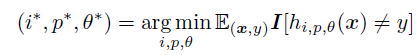
مستطیل های چهره رو به عنوان مثالهای positive در نظر میگیریم. تو شکل زیر اومده:( مثالهای آموزشی مثبت)

و مستطیل هایی که شامل تمام چهره نمیشن ، به عنوان مثالهای آموزشی Negative تلقی میشن. سپس الگوریتم AdaBoost رو اعمال میکینم ، ایشون تعدادی یادگیرنده ی ضعیف رو برمیگردونن ، که هرکدوم از اینا مربوط به یکی از 1 میلیون ویژگی هایی هست که داریم. درواقع اینجا ، AdaBoost می تونه به عنوان یه ابزار واسه انتخاب ویژگی در نظر گرفته بشه.
در ابتدا دو تا ویژگی و موقعیت مربوط به اونا در چهره انتخاب میشه . بدیهی که هر دو ویژگی بصری هستن. که اولین ویژگی اختلاف مقدار شدت روشنایی نواحی چشم و قسمتهای پایین تر از اون رو اندازه گیری میکنه و دومین ویژگی اختلاف مقدار شدت روشنایی نواحی چشمها با نواحی بین چشمها رو اندازه میگیره . با استفاده از ویژگی های انتخاب شده ، یه درخت نامتعادل ساخته میشه که بهش کلاسیفایر Cascade میگن . به شکلها دقت کنین :

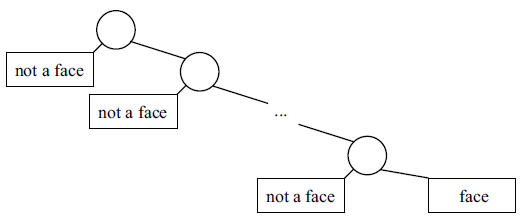
پارامتر در Cascade تنظیم میشه به طوریکه ، در هر نود درخت ، ما یه انشعاب not a face داریم و معنیش اینه که تصویر ، یه تصویر چهره نبوده ، یا به عبارت دیگه ، نرخ false negative داره به حداقل میرسه. ایده ی این طرح در واقع می خواد بگه تصویر غیره چهره زودتر شناسایی میشه. به طور متوسط در هر زیر تصویر 10 تا ویژگی رو مورد بررسی قرار میدیم. اینم تعدادی آزمایش که Viola – Jones روی تصاویر انجام دادن :


البته می شه از جعبه ابزار متلب هم واسه تشخیص چهره با الگوریتم Viola - Jones استفاده کرد به این صورت
close all
clc
%Detect objects using Viola-Jones Algorithm
%To detect Face
FDetect = vision.CascadeObjectDetector;
%Read the input image
I = imread('face3.jpg');
%Returns Bounding Box values based on number of objects
BB = step(FDetect,I);
figure,
imshow(I); hold on
for i = 1:size(BB,1)
rectangle('Position',BB(i,:),'LineWidth',5,'LineStyle','-','EdgeColor','r');
end
title('Face Detection');
hold off;
--------------------------------------------------------------------------------------------------------
ماهیان کوچک چشمانم
آبی چشمان تو را می شناسند
چشمانت را که می بندی
دیوان شعر من
نا تمام می ماند
 اکثر ما موفقیت را قله ای دور از دسترس می بینیم و این گاهی باعث می شود هیچ تمایلی به سعی و تلاش از خود نشان ندهیم. چرا سختی بکشیم وقتی به هر حال این راه طی می شود و به پایان می رسد؟ این تصور از پیروزی اشتباه و مهلک است. اینشتین روز و شب تلاش کرد و بر کاستی ها و مسائل علم فیزیک غلبه کرد اما نه یک شبه! هدفی غایی در ذهن داشت و می دانست با هر گامی که به جلو بر می دارد یک قدم به آن چه در ذهنش دارد نزدیکتر می شود. کار کوچکی که در یک زمان محدود انجام می دهی شاید به نظر بزرگ و مهم نرسد اما بدان که در مقیاس بزرگتر حرکتی است کوچک در مسیری طولانی به سوی هدفی بزرگ !
اکثر ما موفقیت را قله ای دور از دسترس می بینیم و این گاهی باعث می شود هیچ تمایلی به سعی و تلاش از خود نشان ندهیم. چرا سختی بکشیم وقتی به هر حال این راه طی می شود و به پایان می رسد؟ این تصور از پیروزی اشتباه و مهلک است. اینشتین روز و شب تلاش کرد و بر کاستی ها و مسائل علم فیزیک غلبه کرد اما نه یک شبه! هدفی غایی در ذهن داشت و می دانست با هر گامی که به جلو بر می دارد یک قدم به آن چه در ذهنش دارد نزدیکتر می شود. کار کوچکی که در یک زمان محدود انجام می دهی شاید به نظر بزرگ و مهم نرسد اما بدان که در مقیاس بزرگتر حرکتی است کوچک در مسیری طولانی به سوی هدفی بزرگ !